
Sometimes for a batch job you need to process some input where the final list of records to process depends on another list. For example, if you have a folder containing zip files and you need to process each file contained in each zip, or you have a list of accounts from one database and need to process the customer records for these accounts in another database.
There are a number of ways to do this. Here are three ways I have found useful:
- Create a custom reader
- Create an intermediate list
- Use a decider to loop back and process the next item in the high level list
This blog post covers the last of these; the other two were covered in a previous post.
Decider to loop back to earlier step
This method involves storing the initial list in the job’s execution context and having a decider determine whether all of the codes have been processed.
For more information on deciders take a look here.
Using the same scenario as in part 1 (processing a list of customers for account codes retrieved from another data source), there could be a step to read the account codes and store them in the execution context, a step to read the customers for the first account code retrieved from the execution context and process them, and a decider to update the stored list of account codes and return control to the preceding step if there are still codes to be processed.
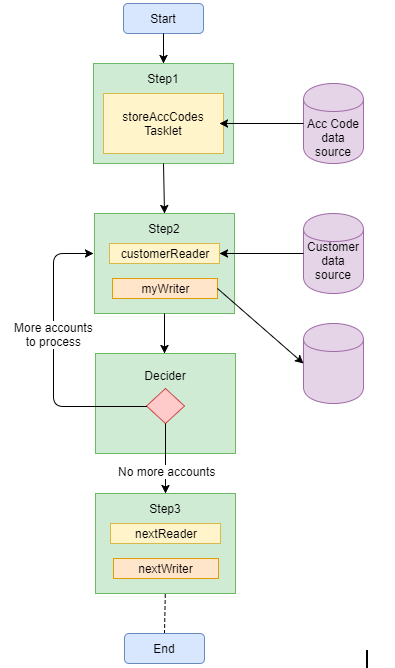
The first step is a tasklet that reads the account codes and stores them in the job execution context like this:
package my.package;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import my.package.MyDao;
public class LoadAccountCodesTasklet implements Tasklet {
private MyDao myDao;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
List<String> accountCodes = myDao.fetchAccountCodes()
// Convert list to comma separated string
String codesStr = String.join(",", accountCodes);
// Store codes in job execution context
chunkContext.getStepContext().getJobExecutionContext()
.put("accountCodes", codesStr );
// update counts in step context to reflect number of codes read and stored
contribution.incrementReadCount(accountCodes.size());
contribution.incrementWriteCount(accountCodes.size());
return RepeatStatus.FINISHED;
}
public void setMyDao(MyDao myDao) {
this.myDao = myDao;
}
}The second step has a reader that retrieves the customers for the current account code like this:
package my.package;
import org.springframework.batch.item.NonTransientResourceException;
import org.springframework.batch.item.ParseException;
import org.springframework.batch.item.UnexpectedInputException;
import org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.batch.item.support.IteratorItemReader;
import my.package.MyDao;
import my.package.MyPojo;
public class CustomerReader extends AbstractItemCountingItemStreamItemReader<MyPojo> {
private MyDao myDao;
private String accountCodes;
private IteratorItemReader<MyPojo> list;
@Override
public MyPojo doRead() throws Exception, UnexpectedInputException,ParseException, NonTransientResourceException {
return list.read();
}
@Override
protected void doOpen() throws Exception {
// Determine the account code to use - up to the first comma
int pos = accountCodes.indexOf(',');
String accCode = (pos == -1) ? accountCodes : accountCodes.substring(0, pos);
list = new IteratorItemReader<MyPojo>(myDao.fetchMyPojos(accCode));
}
@Override
protected void doClose() throws Exception {
// Nothing to do here
}
public void setMyDao(MyDao myDao) {
this.myDao = myDao;
}
public void setAccountCodes(String accountCodes) {
this.accountCodes = accountCodes;
}
}This requires the list of account codes stored in the job execution context to be passed in to the reader. This can be done in the configuration:
<bean id="customerReader" class="my.package.CustomerReader" scope="step">
<property name="myDao" ref="myDao"/>
<property name="accountCodes" value="#{jobExecutionContext['accountCodes']}"/>
</bean>It is vital to set the scope of the reader bean to “step”, otherwise you won’t be able to reference the jobExecutionContext value. It is also important to make sure that you specify the same value name that was used to store the codes in the LoadAccountCodesTasklet class.
Lastly, a decider is required to remove the first code from the stored list of account codes and return a status that will be used to determine which step to execute next. Something like this:
package my.package;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.job.flow.FlowExecutionStatus;
import org.springframework.batch.core.job.flow.JobExecutionDecider;
public class AccountCodeFlowDecider implements JobExecutionDecider {
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String accountCodes = jobExecution.getExecutionContext().getString("accountCodes");
// Determine the account code to remove - up to the first comma
int pos = accountCodes.indexOf(',');
accountCodes = (pos == -1) ? "" : accountCodes.substring(pos+1);
jobExecution.getJobExecutionContext().put("accountCodes", accountCodes);
FlowExecutionStatus status = (pos > -1) ?
status = new FlowExecutionStatus("ANOTHER") : FlowExecutionStatus.COMPLETED;
return status;
}
}The status returned from the decider will be used to control the processing in the job.
The job definition for the decider might include something like this:
<decision id="checkMoreAccountCodesDecision" decider="accountCodeFlowDecider">
<next on="ANOTHER" to="step2"/>
<next on="*" to="step3"/>
</decision>This configuration will return control to step2 in order to process the next account code if there is still another code to process. If all the codes have been processed, the job will move on to step3.
Using this approach will result in the Spring Batch tables containing records for the steps that process the customers multiple times – once for each account code.
Conclusion
This may seem a complicated way to process a list of customers for a list of account codes.
As described here there is only one step executed, but if the requirement is to process the customers for each account code through a number of steps before progressing to the next account code, then this could be a suitable approach to take.
I have also used this principle when I needed one job to call another multiple times with different parameters. We had one job that processed records for a particular account. We then needed to process records for a list of accounts, so we created a simple second job that stored the list of account codes in the execution context with one main step to invoke the original job.
Over the two posts for this topic I have described three ways to process a list of lists:
- Create a custom reader
- Create an intermediate list
- Use a decider to loop back and process the next item in the high level list
The first two options are described in part 1.
The first option is appropriate when the data is stable and the job will not need to be stopped and restarted.
The second option is best if the data is volatile, as you have taken a snapshot of the records to be processed. This is the option I usually choose.
The third option is appropriate if the records for one list need to be taken through a number of steps before processing the next list, such as processing the customers for one account before processing those for another account.

Can i get source code for this?
very good to understand.thanks for the blog
Hi Jai,
The source code to implement what is discussed is included in the blog. If you need a tutorial on getting starting with Spring Batch, there are plenty of other tutorial blogs available.
Can i get source code for this?
Very interesting, thank you!