
Sometimes for a batch job you need to process some input where the final list of records to process depends on another list. For example, if you have a folder containing zip files and you need to process each file contained in each zip, or you have a list of accounts from one database and need to process the customer records for these accounts in another database.
There are a number of ways to do this. Here are three ways I have found useful:
This blog post covers the first two of these; the decider will be covered in another post.
You could create a reader to handle the two sets of lists. The reader could retrieve its account codes from another reader and then use a Dao class to look up the customer records for each code.
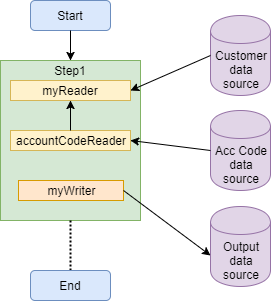
Such a reader class could look like this:
package my.package.reader;
import java.util.List;
import org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.batch.item.support.IteratorItemReader;
import my.package.MyDao;
import my.package.MyPojo;
public class MyReader extends AbstractItemCountingItemStreamItemReader<MyPojo> {
private MyDao myDao;
private IteratorItemReader<MyPojo> list;
private ItemReader<String> accountCodeReader;
private String currentAccountCode;
@Override
protected MyPojo doRead() throws Exception {
// Get next item from list for current account code
MyPojo item = list.read();
// If no more items for the current account code,
// then fetch the items for the next account code
if (item == null) {
fetchRecs();
item = list.read();
}
return item;
}
@Override
protected void doOpen() throws Exception {
// Take the first account code
// and fetch the records for that key
currentAccountCode = accountCodeReader.read();
fetchRecs();
}
protected void fetchRecs() throws Exception {
List<MyPojo> items = null;
// Fetch the items for next account codes until the
// last account code has been processed, or some items are found
while (items.size() == 0 && currentAccountCode != null) {
items = myDao.fetchMyPojos(currentAccountCode);
if (items.size() == 0) {
currentAccountCode = accountCodeReader.read(); }
}
// Store the items in an ItemReader used in the doRead() method
list = new IteratorItemReader<MyPojo>(items);
}
@Override
protected void doClose() throws Exception {
// Nothing to do here
}
public void setMyDao(MyDao myDao) {
this.myDao = myDao;
}
public void setAccountCodeReader( ItemReader<String> accountCodeReader) {
this.accountCodeReader = accountCodeReader;
}
}If you’re using XML to configure the job, then you will need to define a reader bean like this:
<bean id="myReader" class="my.package.MyReader" scope="step">
<property name="accountCodeReader" ref="accountCodeReader"/>
<property name="myDao" ref="myDao"/>
</bean>
This example reader class extends the AbstractItemCountingItemStreamItemReader class. This includes logic to store how many records have been read in the step execution context, meaning that you can stop and restart the job and the processing will pick up from the last processed record.
This is fine if the data you are reading is not volatile. However, if the job is stopped and data might have changed between the step initially starting and subsequently restarting, then this approach may cause problems. An alternative could be to create a reader that implements the ItemReader interface, rather than extending the AbstractItemCountingItemStreamItemReader class, if it is acceptable to process all the records again and not pick up from somewhere in the middle of the list.
Another way would be to have one step to convert the initial list into the final list of items to process. Then a second step would read the full list and process the items.
Let’s take the previous example to process the customer records for a list of account codes.
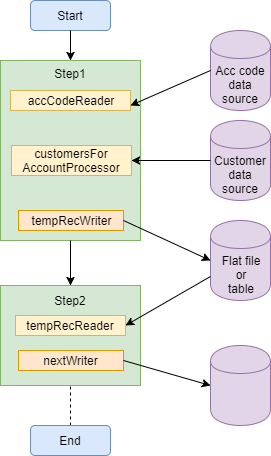
In this scenario, the job steps would be defined like this:
<step id="defineFullList" next="readFullList">
<tasklet transaction-manager="transactionManager">
<chunk reader="accountCodeReader"
processor=”customersForAccountProcessor”
writer="tempRecordsWriter"/>
</tasklet>
</step>
<step id="readFullList" next="myNextStep">
<tasklet transaction-manager="transactionManager">
<chunk reader="tempRecordsReader"
processor=”myCustomerProcessor”
writer="customerWriter"/>
</tasklet>
</step>In the first step the reader supplies the account codes for a processor, which is a simple processor that calls the Dao method to retrieve the customers for an account code. Something like this:
package my.package;
import java.util.List;
import my.package.MyDao;
import my.package.MyPojo;
import org.springframework.batch.item.ItemProcessor;
public class CustomersForAccountProcessor implements ItemProcessor<String, List<MyPojo>> {
private MyDao myDao;
@Override
public List<MyPojo> process(String item) throws Exception {
return myDao.fetchMyPojos(item);
}
public void setMyDao(MyDao myDao) {
this.myDao = myDao;
}
}The tempRecordsWriter would store each list in some form of temporary storage, such as a CSV file or temporary database table. As the output of the processor is a List, the input to the writer will be a List of Lists.
I have found it useful to utilise a writer that takes a list of lists and passes each of the nested lists to another writer to perform the actual writing:
package my.package;
import java.util.List;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.batch.item.ItemStream;
import org.springframework.batch.item.ItemStreamException;
import org.springframework.batch.item.ItemWriter;
public class ListDelegateWriter<T> implements ItemWriter<List<T>>, ItemStream {
private ItemWriter<T> delegate;
@Override
public void write(List<? extends List<T>> items) throws Exception {
for (List<T> item : items) {
delegate.write(item);
}
}
public void setDelegate(ItemWriter<T> delegate) {
this.delegate = delegate;
}
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
if (delegate instanceof ItemStream) {
((ItemStream) delegate).open(executionContext);
}
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
if (delegate instanceof ItemStream) {
((ItemStream) delegate).update(executionContext);
}
}
@Override
public void close() throws ItemStreamException {
if (delegate instanceof ItemStream) {
((ItemStream) delegate).close();
}
}
}If you’re using XML to configure the job, the writer definition would look like this:
<bean id="tempRecordsWriter" class="my.package.ListDelegateWriter" scope="step">
<property name="delegate" ref="tempCustomerWriter"/>
</bean>The tempCustomerWriter bean could be a FlatFileItemWriter, or another of your choosing.
The tempRecordsReader would be a simple reader to retrieve the customer records for use in the subsequent processing.
This option is ideal if the list is volatile and the job may have to be stopped and restarted.
Of these two ways to achieve the processing of lists of lists, for me the appropriate solution is determined by whether the job is required to be restartable and how volatile the data is.
I generally go for the intermediate list unless there is a reason not to. Using this method with a flat file as the storage medium also results in a record of what was actually processed in the job, which is useful for audit purposes.
In the next post I’ll describe how to process lists of lists using a decider to control the flow of processing.
For a description of the Spring Batch framework please take a look here.












