
In the latest post in his ‘Spring Batch’ series, Jeremy Yearron runs through some best practice for splitting data batch jobs into smaller steps.
 Spring Batch in smaller steps
Spring Batch in smaller stepsWhen designing a batch job, it is not always straightforward to know how to split the job into a set of steps, or sometimes it seems quite easy but you end up with a situation that seems good at first but ends up working against you.
Let’s take an example: you need to create a job that will process a number of zip files (about 1GB in size) that each contain about 100 XML files. The files are to be downloaded from a website. The XML files are to be parsed, the relevant data extracted, and written to a CSV file to be imported into a database table.
This example is based on a real-world requirement for a job I had a few years ago.
It would be possible to create a job that meets these requirements which only has one step, by identifying a file, downloading it and processing it before doing the same for the next file on the web site. However, there is a risk that the web session will time out between downloading one file and trying to download the next one. It would be better to download all the files and then process them one by one.
So, we could have a job like this:
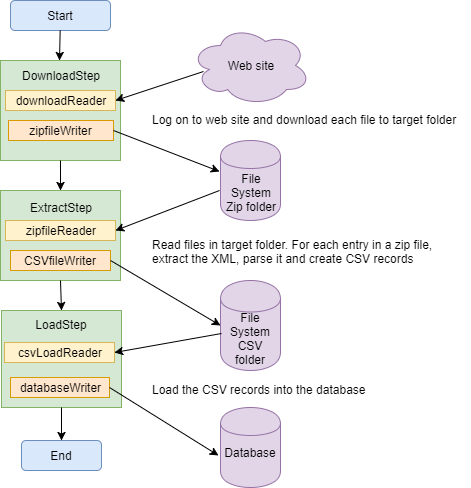
This means that we shouldn’t have to worry about session timeout. This is better, but what if the list of files on the web site is quite volatile? If you have a connection problem when downloading one of the files, there might be additional files on the page when you come to restart the job, so you retrieve more files than you originally expected. This might be a problem for you, or it might not.
An option would be to break the download into smaller steps:
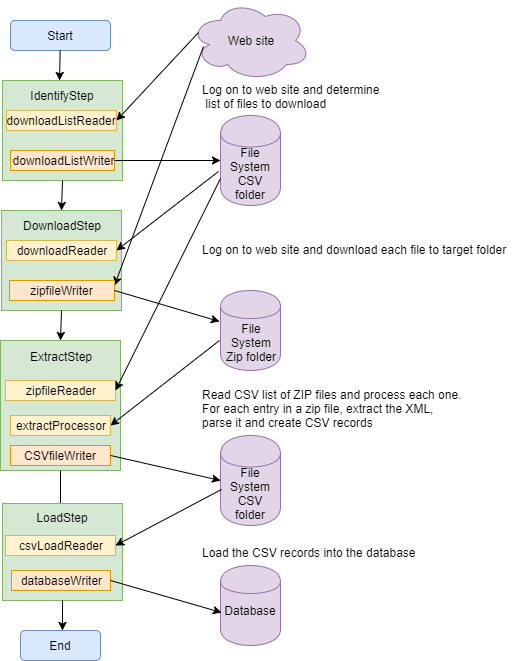
So now we get a snapshot of the files we will be processing at the start of the job and then process them. By using the list of files to be downloaded to identify the files to be extracted, we can be sure that all of the expected data has been processed. The job will fail if any file is accidentally moved out of the target folder, and will ignore any file in the target folder that was not previously downloaded as part of this job run.
So far, so good. The download part of the job is better than before, but what about the extract step?
The Zip files are quite large – about 1GB. To identify each XML file within a zip file, extract the data, parse it and create CSV records is a fair amount of work. If you are using a framework like Spring Batch, this will help you track the processing of each zip file, but not for each XML file. If the job fails parsing an XML file, when you come to restart the job, it could be difficult to resume processing from the XML file that failed – you would have to manually keep track of which XML files had been processed, and identify the XML file in the zip to start reading from.
A better way would be to have a step to catalog the XML files in each zip file in another CSV file, containing the zip file name and the entry name. Then the extract step will be taking each XML file in turn and be able to track the progress at that level. A helper class can be used to hold the current position within the current zip file and read forward to find the next entry, or switch to a different zip file if the CSV record is for the next zip file.
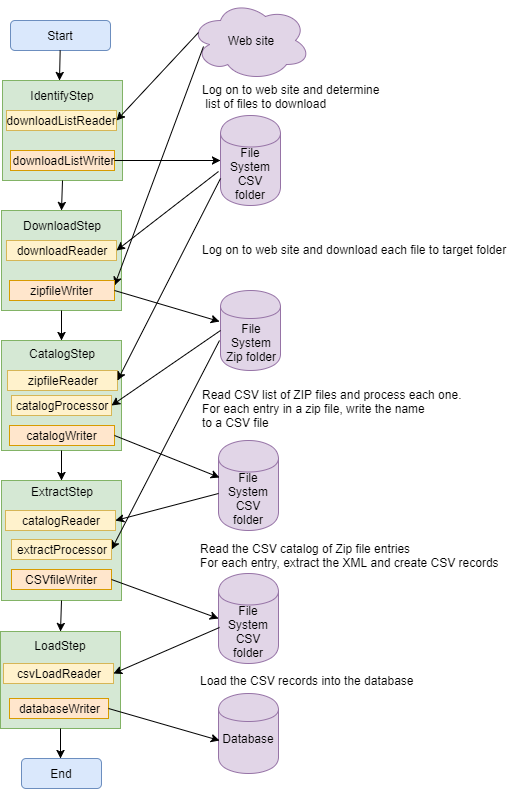
Now, if the job fails parsing an XML file, we can restart the job, knowing which XML file is to be processed first.
The downside to using a catalog file is that you are reading each zip file twice, but I find that the extra time spent is worth it, as you have more fine grained control over the extract processing.
I have found that with this example scenario, as with many others, that it pays dividends to take some time to break a job down into a number of small steps, rather than a few bigger steps.
I recommend that you try to do this whenever possible.
Jeremy’s Spring Batch posts (Season 1)
Lots of data? Multiple batches? Sounds like a job for Spring Batch.
Log the record count during processing
How to read list of lists (part I)
How to read list of lists (part II)
Plus..












