
Jeremy Yearron has been using the Spring Batch framework to manage complex data tasks on behalf of client organisations for many years, involving the building of batch jobs. He has begun to chronicle and share some of the key lessons in a series of blog posts. This content is written for advanced users of the framework and seeks to answer the more niche questions that have come up along the way.
Here is no.1 and there are more in the pipeline…
For a description of the Spring Batch framework, take a look here.
When creating a batch job, the requirement is usually for a single job to process a number of records.
However, it is often useful to have a number of variations of the job:
I have found the ability to process a selected list of record particularly useful for testing, where you can run jobs that process records with certain conditions. This variation can be used as part of a set of tests, for instance, if the final testing will be against a copy of live data that changes over time then certain records that illustrate particular conditions can be picked out.
A job to process a single record enables you to focus on one specific record. Having a job to do this will prove invaluable when you need to investigate an issue. I recommend including a lot of logging in the code so that the job can give you a commentary on everything that it is doing. Turn up the logging for the single record job and the log will give you an insight into what is happening in the job. Have the logging turned down for the jobs that process a number of records, otherwise you will be overloaded with information.
There are a number of ways to set up different variations of a Spring Batch job. For example, you could create a custom reader, use a decider to choose between readers or create different jobs
One way would be to use parameters to identify the type of run, with a custom reader to access the appropriate data according to the parameter defining the job type.
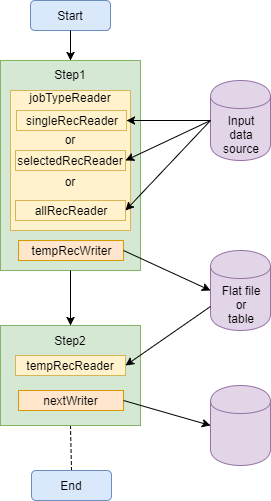
Such a reader class could look like this:
package my.package;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.job.flow.FlowExecutionStatus;
import org.springframework.batch.core.job.flow.JobExecutionDecider;
public class JobTypeDecider implements JobExecutionDecider {
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
JobParameters params = jobExecution.getJobParameters();
return new FlowExecutionStatus(params.getString("jobType"));
}
}If you’re using XML to configure the job, then you will need to define a reader like this:
<bean id="jobTypeReader" class="my.package.JobTypeReader" scope="step">
<property name="jobType" value="#{jobParameters[jobType]}"/>
<property name="allRecordsReader" ref="allRecordsReader"/>
<property name="selectedRecordsReader" ref="selectedRecordsReader"/>
<property name="singleRecordReader" ref="singleRecordReader"/>
</bean>
The jobType property is set to the jobType parameter. In order for this to work, the reader must have its scope attribute set to “step”.
The reader class will only access the required data source. If the allRecordsReader, the selectedRecordsReader or the singleRecordReader implement the ItemStream interface, then your JobType class will also have to implement the ItemStream interface, and will require a similar switch statement in the implementations of the methods in that interface: open; update and close.
An alternative could be to define a step for each different variation and have a decider choose the appropriate reader to use. If each of these variant specific steps writes the records to a temporary table or a CSV file, then the subsequent steps can process the required records regardless of the type of job being run.
For more information on deciders, see https://docs.spring.io/spring-batch/reference/html/configureStep.html#programmaticFlowDecisions
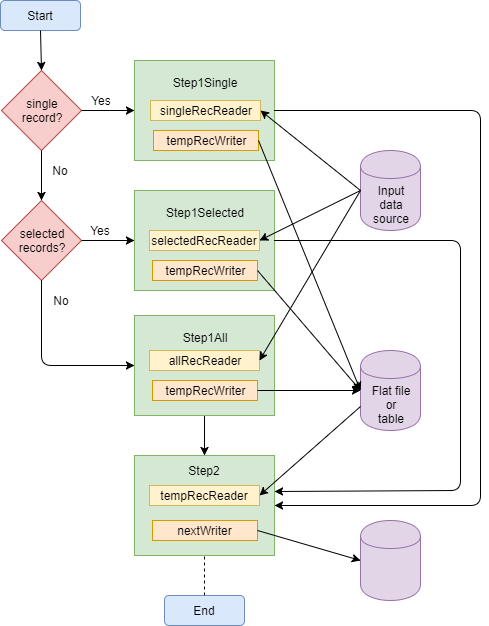
The job definition might include something like this:
<decision id="chooseReaderDecision" decider="jobTypeDecider">
<next on="SINGLE" to="readSingleRecord"/>
<next on="SELECTED" to="readSelectedRecords"/>
<next on="*" to="readAllRecords"/>
</decision>
<step id="readSingleRecord" next="myNextStep">
<tasklet transaction-manager="transactionManager">
<chunk reader="singleRecordReader" writer="tempRecordsWriter"/>
</tasklet>
</step>
<step id="readSelectedRecords" next="myNextStep">
<tasklet transaction-manager="transactionManager">
<chunk reader="selectedRecordsReader" writer="tempRecordsWriter"/>
</tasklet>
</step>
<step id="readAllRecords" next="myNextStep">
<tasklet transaction-manager="transactionManager">
<chunk reader="allRecordsReader" writer="tempRecordsWriter"/>
</tasklet>
</step>
<step id="myNextStep" next="anotherStep">
<tasklet transaction-manager="transactionManager">
<chunk reader="tempRecordsReader" writer="..."/>
</tasklet>
</step>
The jobTypeDecider bean would be a class implementing the JobExecutionDecider interface that returns a FlowExecutionStatus of SINGLE, SELECTED or something else. Any value other than SINGLE or SELECTED will be taken to mean that all records should be processed.
For example a decider class such this will return a status FlowExecutionStatus representing the value of the jobType parameter for the job.
package my.package;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.job.flow.FlowExecutionStatus;
import org.springframework.batch.core.job.flow.JobExecutionDecider;
public class JobTypeDecider implements JobExecutionDecider {
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
JobParameters params = jobExecution.getJobParameters();
return new FlowExecutionStatus(params.getString("jobType"));
}
}
The job should be launched with the jobType parameter set to “SINGLE”, “SELECTED” or “ALL” depending on which variant you wish to run.
In some situations, however, it may be more appropriate to create separate jobs for each variation. It depends on your situation.
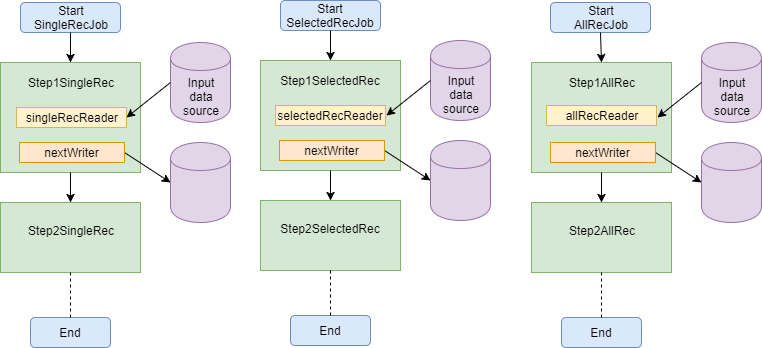
One drawback of using this approach is that each step can only be defined once in an application context XML file. However, there is a way to get round this.
You can define your steps outside of a job and then “inherit” their definition using the parent attribute. See https://docs.spring.io/spring-batch/reference/html/configureStep.html#InheritingFromParentStep for more details.
In each of your jobs you create steps that point to a parent step definition. Therefore, if you change the parent step, each job will pick up the change.
Alternatively, you could define new steps for each variant of the job, but doing that would mean that a change to a step in one job would require the same change to be made to the jobs for the other variants.
As you can see, there are a number of ways to implement different variations of the same job.
For me, taking this approach has been very beneficial and, particularly the single record job has saved me a significant amount of time trying to get to the bottom of an issue in testing and, occasionally, in production.












